Learning GRPO: Experiments and Insights from Fine-Tuning an LLM
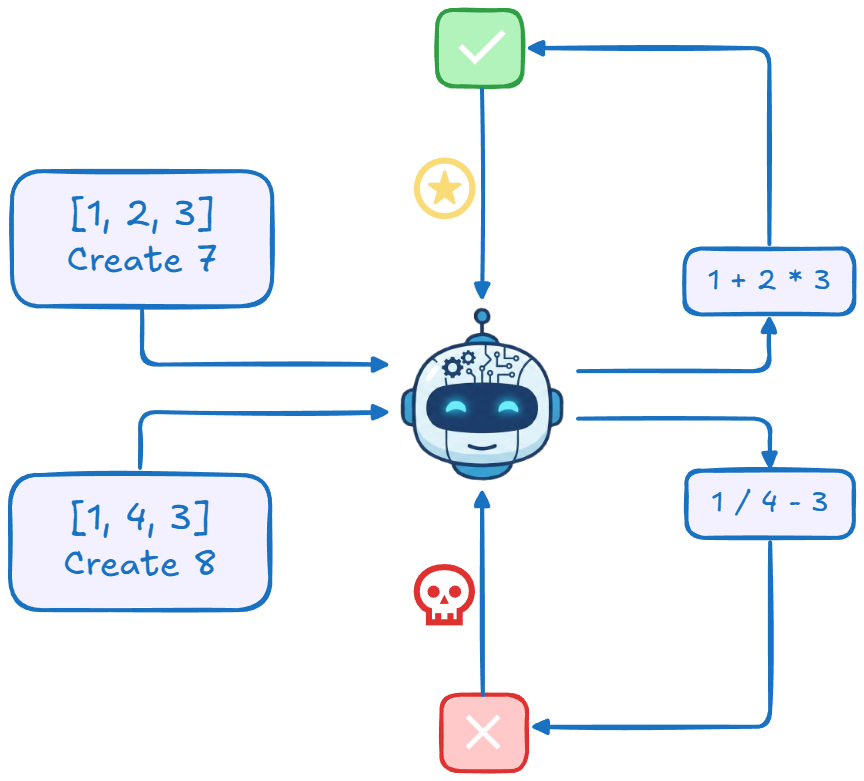
This blog documents a series of experiments and results on training an LLM on a toy arithmetic task called Countdown.
This blog documents a series of experiments and results on training an LLM on a toy arithmetic task called Countdown.